Welcome to NVIDIA FLARE
What is Federated Learning?
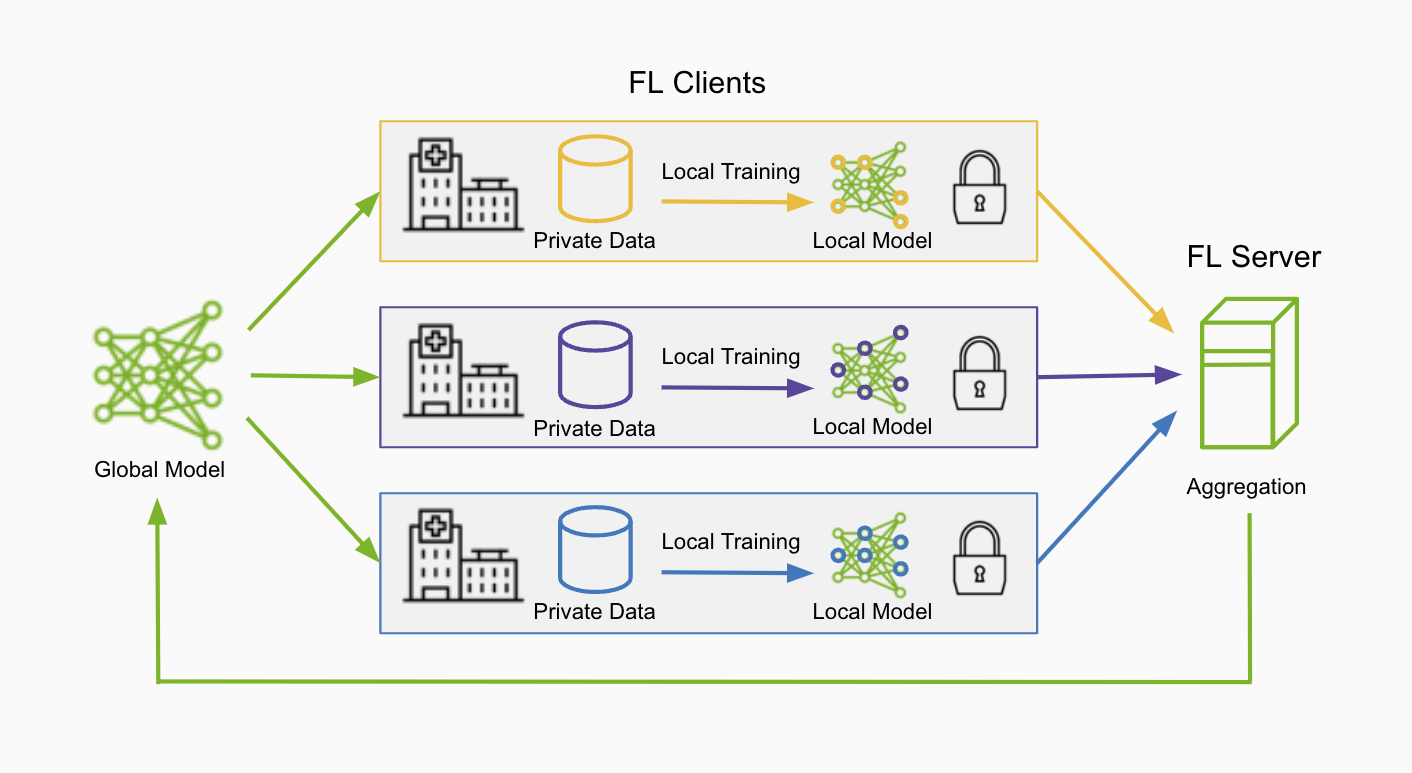
Federated Learning is a distributed learning paradigm where training occurs across multiple clients, each with their own local datasets. This enables the creation of common robust models without sharing sensitive local data, helping solve issues of data privacy and security.
The FL server orchestrates the collaboration by sending an initial model to clients. Clients train on their local data and send model updates back for aggregation into a global model. After multiple rounds, a robust global model is developed – all without any raw data leaving its source.
Types of Federated Learning:
Horizontal FL – Clients hold different data samples over the same features
Vertical FL – Clients hold different features over overlapping data samples
Swarm Learning – Decentralized FL where clients perform aggregation without a central server
What is NVIDIA FLARE?
NVIDIA FLARE (NVIDIA Federated Learning Application Runtime Environment) is a domain-agnostic, open-source, extensible Python SDK that makes it easy to bring federated learning to your existing ML/DL workflows.
Get started in minutes – FLARE is designed so that data scientists can convert their existing training code to federated with minimal effort:
Use the Client API to add just a few lines to your existing training script
Use the Job Recipe API to pick a pre-built FL algorithm and run it immediately
Use the FL Simulator to test everything locally before deploying
Here is a complete federated averaging job in just a few lines:
from nvflare.app_opt.pt.recipes import FedAvgRecipe
from nvflare.recipe import SimEnv
recipe = FedAvgRecipe(
name="my-first-fl-job",
min_clients=2,
num_rounds=5,
model=MyModel(),
train_script="train.py",
)
run = recipe.execute(SimEnv(num_clients=2))
FLARE supports PyTorch, TensorFlow, XGBoost, scikit-learn, and any framework that can run in Python. It scales from a single laptop (Simulator) to thousands of distributed sites (Production) to millions of edge devices – all using the same job definition.
Why NVIDIA FLARE?
NVIDIA FLARE is built for real-world production deployments, not just research prototyping.
vs. Research-Only Frameworks: Unlike research-oriented FL frameworks, FLARE provides a complete production stack: secure provisioning with PKI certificates, fine-grained authorization policies per site, audit logging, confidential computing with hardware TEEs, and deployment tooling for Docker, Kubernetes, and cloud environments. Organizations including hospitals, national labs, and financial institutions run FLARE in production today (see Industry Use Cases).
Key Differentiators:
Minimal code changes – The Client API lets you federate existing training scripts by adding a few lines, not rewriting your code
Production security – TLS/mTLS, per-site authorization policies, differential privacy, homomorphic encryption, and hardware-backed confidential computing (AMD SEV-SNP, NVIDIA GPU TEEs)
Scale – From 2 sites to millions of edge devices with hierarchical architecture
Framework agnostic – PyTorch, TensorFlow, XGBoost, scikit-learn, HuggingFace, NeMo, Flower
Proven in production – Used by healthcare consortia, national security labs, and financial institutions
Key Features
Built for Productivity
Client API – Convert existing training code to federated with minimal changes
Job Recipe API – Pre-built recipes for FedAvg, FedProx, SCAFFOLD, XGBoost, Cyclic, and more
FL Simulator – Rapid prototyping on a single machine
POC Mode – Multi-process simulation of a federated network on one host
FLARE API – Run and monitor jobs from Python code or notebooks
Dashboard – Web UI for project setup and deployment artifact distribution
Experiment Tracking – MLflow, Weights & Biases, and TensorBoard
Built for Security & Privacy
Secure Provisioning – TLS certificate-based authentication
Authorization Policies – Fine-grained, site-controlled authorization
Privacy Preservation – Differential privacy, homomorphic encryption, private set intersection
Confidential Computing – Hardware-backed TEEs with AMD SEV-SNP and NVIDIA GPU support
Audit Logging – Complete audit trail for accountability
Built for Scale
Framework Agnostic – PyTorch, TensorFlow, XGBoost, scikit-learn, and more
Cross-Silo to Edge – From a handful of hospital sites to millions of mobile devices
Hierarchical Architecture – Multi-region, tiered FL for large-scale deployments
Multi-Job Execution – Concurrent job execution with resource management
3rd-Party Integration – FlareAgent for seamless integration with external systems
Built for Customization
Event-Driven Plugin Architecture – Every layer of FLARE is customizable through an event system and component plugins. Intercept, modify, or extend any stage of the FL workflow
Specification-Based APIs – Build alternative implementations following well-defined specs for controllers, aggregators, filters, executors, and more
Pluggable Components – Swap aggregation strategies, privacy filters, model persistors, and communication backends without changing application code
Rich Examples – Extensive library of FL algorithms, workflows, and application examples to build from
What is New in 2.8.0
NVIDIA FLARE 2.8.0 expands deployment automation, CLI operations, multi-study support, and production hardening while adding Docker and Kubernetes job launchers for on-premises and cloud environments plus new multimodal and research examples.
Highlights:
Modern NVFlare CLI: expanded
job,system,config,recipe,cert,package, anddeploycommand groups with JSON output and schema support for automationDistributed Provisioning: participant-managed certificate requests keep private keys local while Project Admins approve signed packages and root CA trust
Docker and Kubernetes Job Launchers: sites can configure process, Docker, or Kubernetes job launchers for subprocess jobs, job containers, or isolated job pods with study-scoped dataset mounts, including Kubernetes deployments on AWS, Azure, and GCP
Multi-Study Support: study-scoped sessions, authorization, CLI commands, and local PoC workflows let one deployment host multiple collaborations without mixing operational or data-access context
Live Log Streaming: client job logs stream to the server while jobs are running, shortening remote debugging loops
See What’s New in FLARE v2.8.0 for full release notes. See Previous Releases of FLARE for previous releases.
Real-World Use Cases & FLARE Day
See how organizations use NVIDIA FLARE in production across healthcare, autonomous driving, finance, and more:
FLARE Day 2025 – Real-world FL applications in healthcare, finance, autonomous driving, and more
FLARE Day 2024 – Talks and demos featuring real-world FL deployments at NVIDIA, healthcare institutions, and industry partners
Real-World FL Research – Published research and industry applications built with FLARE
Learn More
Tutorial Website – Video tutorials, code walkthroughs, and the example catalog
Example Catalog – Browse examples by framework, algorithm, and use case
Self-Paced Training – 100+ notebooks and 80 videos for comprehensive self-paced learning
Product Lines
FLARE consists of three product categories:
- FLARE Core
The full federated learning platform: communication infrastructure, workflows, controllers, Client API, Recipe API, FL Simulator, provisioning, deployment, and management tools.
- FLARE Confidential AI
Confidential Federated AI with hardware-backed security. Leverages Trusted Execution Environments (AMD SEV-SNP, Intel TDX) and NVIDIA GPU confidential computing for end-to-end IP protection. Supports both on-premises and Azure cloud deployments.
- FLARE Edge
Federated learning at the edge, supporting millions of devices with hierarchical architecture, asynchronous aggregation (FedBuff), device simulation, and mobile SDKs for Android and iOS (via ExecuTorch).